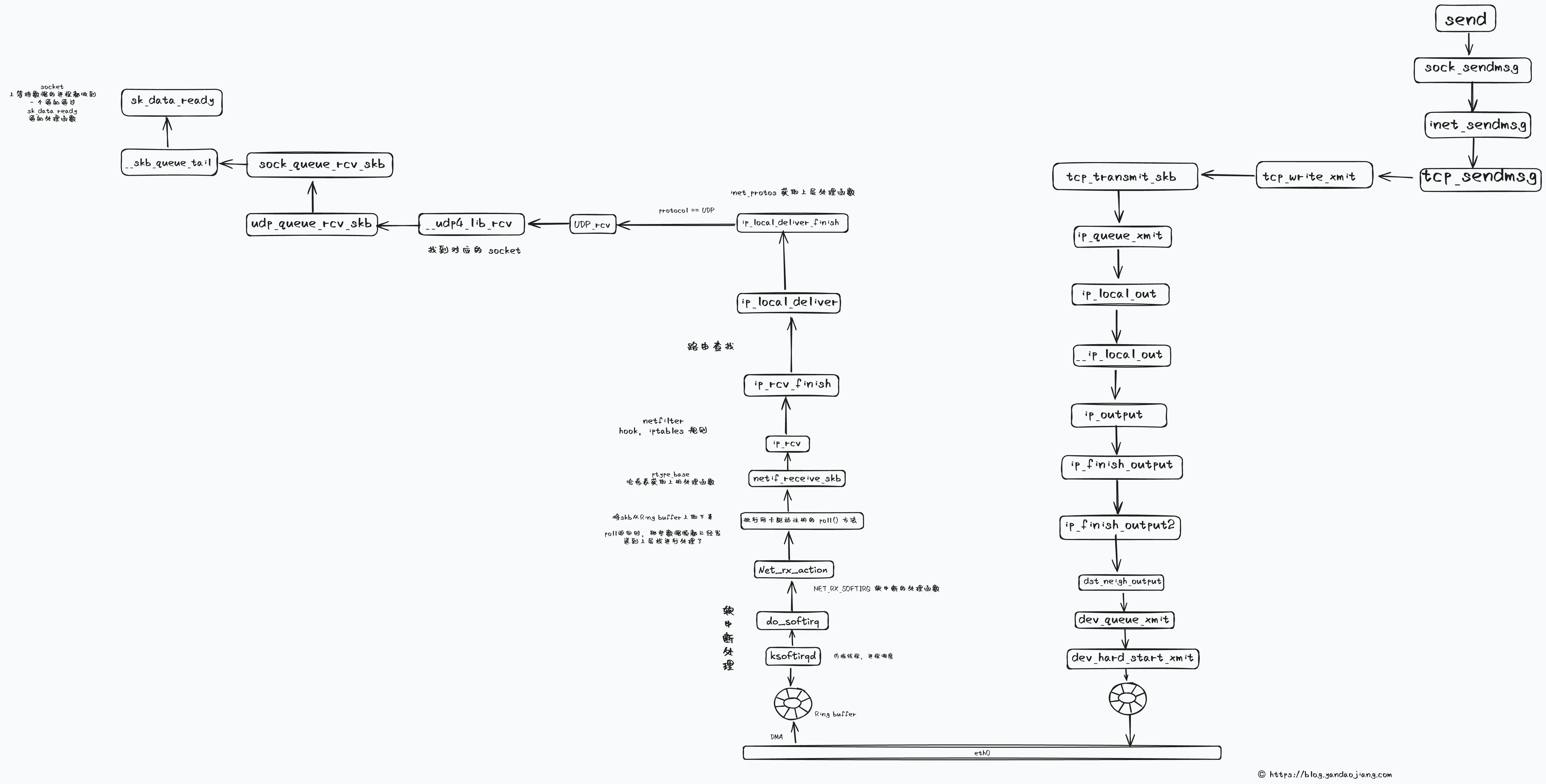
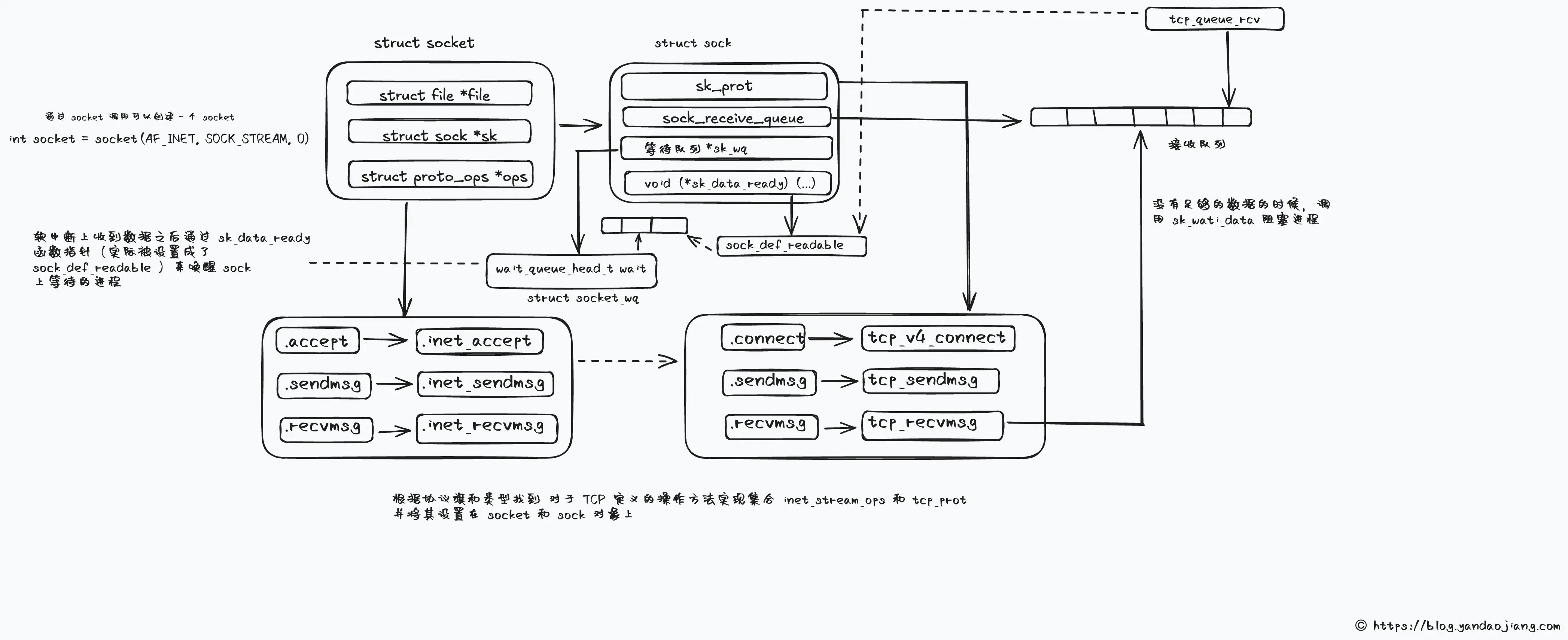
// https://github.com/torvalds/linux/blob/8bb495e3f02401ee6f76d1b1d77f3ac9f079e376/net/ipv4/af_inet.c#L760-L773
intinet_sendmsg(structkiocb*iocb,structsocket*sock,structmsghdr*msg,size_tsize){structsock*sk=sock->sk;sock_rps_record_flow(sk);/* We may need to bind the socket. */if(!inet_sk(sk)->inet_num&&!sk->sk_prot->no_autobind&&inet_autobind(sk))return-EAGAIN;returnsk->sk_prot->sendmsg(iocb,sk,msg,size);}
// https://github.com/torvalds/linux/blob/8bb495e3f02401ee6f76d1b1d77f3ac9f079e376/net/ipv4/tcp.c#L1016-L1241
inttcp_sendmsg(structkiocb*iocb,structsock*sk,structmsghdr*msg,size_tsize){structiovec*iov;structtcp_sock*tp=tcp_sk(sk);structsk_buff*skb;intiovlen,flags,err,copied=0;intmss_now=0,size_goal,copied_syn=0,offset=0;boolsg;longtimeo;lock_sock(sk);flags=msg->msg_flags;if(flags&MSG_FASTOPEN){err=tcp_sendmsg_fastopen(sk,msg,&copied_syn);if(err==-EINPROGRESS&&copied_syn>0)gotoout;elseif(err)gotoout_err;offset=copied_syn;}timeo=sock_sndtimeo(sk,flags&MSG_DONTWAIT);/* Wait for a connection to finish. One exception is TCP Fast Open
* (passive side) where data is allowed to be sent before a connection
* is fully established.
*/if(((1<<sk->sk_state)&~(TCPF_ESTABLISHED|TCPF_CLOSE_WAIT))&&!tcp_passive_fastopen(sk)){if((err=sk_stream_wait_connect(sk,&timeo))!=0)gotodo_error;}if(unlikely(tp->repair)){if(tp->repair_queue==TCP_RECV_QUEUE){copied=tcp_send_rcvq(sk,msg,size);gotoout;}err=-EINVAL;if(tp->repair_queue==TCP_NO_QUEUE)gotoout_err;/* 'common' sending to sendq */}/* This should be in poll */clear_bit(SOCK_ASYNC_NOSPACE,&sk->sk_socket->flags);mss_now=tcp_send_mss(sk,&size_goal,flags);/* Ok commence sending. */iovlen=msg->msg_iovlen;// 用户空间数据长度
iov=msg->msg_iov;// 用户空间数据地址
copied=0;err=-EPIPE;if(sk->sk_err||(sk->sk_shutdown&SEND_SHUTDOWN))gotoout_err;sg=!!(sk->sk_route_caps&NETIF_F_SG);// 遍历用户空间数据
while(--iovlen>=0){size_tseglen=iov->iov_len;unsignedchar__user*from=iov->iov_base;// 待发送数据的地址
iov++;if(unlikely(offset>0)){/* Skip bytes copied in SYN */if(offset>=seglen){offset-=seglen;continue;}seglen-=offset;from+=offset;offset=0;}while(seglen>0){intcopy=0;intmax=size_goal;// 获取发送队列的尾部
skb=tcp_write_queue_tail(sk);if(tcp_send_head(sk)){if(skb->ip_summed==CHECKSUM_NONE)max=mss_now;copy=max-skb->len;}if(copy<=0){new_segment:/* Allocate new segment. If the interface is SG,
* allocate skb fitting to single page.
*/if(!sk_stream_memory_free(sk))gotowait_for_sndbuf;// 申请一个新的 skb,并添加到发送队列尾部
skb=sk_stream_alloc_skb(sk,select_size(sk,sg),sk->sk_allocation);if(!skb)gotowait_for_memory;/*
* Check whether we can use HW checksum.
*/if(sk->sk_route_caps&NETIF_F_ALL_CSUM)skb->ip_summed=CHECKSUM_PARTIAL;// 将新的 skb 添加到发送队列尾部
skb_entail(sk,skb);copy=size_goal;max=size_goal;}/* Try to append data to the end of skb. */if(copy>seglen)copy=seglen;/* Where to copy to? */if(skb_availroom(skb)>0){/* We have some space in skb head. Superb! */copy=min_t(int,copy,skb_availroom(skb));err=skb_add_data_nocache(sk,skb,from,copy);// 将数据拷贝到 skb 中
if(err)gotodo_fault;}else{boolmerge=true;inti=skb_shinfo(skb)->nr_frags;structpage_frag*pfrag=sk_page_frag(sk);if(!sk_page_frag_refill(sk,pfrag))gotowait_for_memory;if(!skb_can_coalesce(skb,i,pfrag->page,pfrag->offset)){if(i==MAX_SKB_FRAGS||!sg){tcp_mark_push(tp,skb);gotonew_segment;}merge=false;}copy=min_t(int,copy,pfrag->size-pfrag->offset);if(!sk_wmem_schedule(sk,copy))gotowait_for_memory;err=skb_copy_to_page_nocache(sk,from,skb,pfrag->page,pfrag->offset,copy);if(err)gotodo_error;/* Update the skb. */if(merge){skb_frag_size_add(&skb_shinfo(skb)->frags[i-1],copy);}else{skb_fill_page_desc(skb,i,pfrag->page,pfrag->offset,copy);get_page(pfrag->page);}pfrag->offset+=copy;}if(!copied)TCP_SKB_CB(skb)->tcp_flags&=~TCPHDR_PSH;tp->write_seq+=copy;TCP_SKB_CB(skb)->end_seq+=copy;skb_shinfo(skb)->gso_segs=0;from+=copy;copied+=copy;if((seglen-=copy)==0&&iovlen==0)gotoout;if(skb->len<max||(flags&MSG_OOB)||unlikely(tp->repair))continue;// 发送判断,满足条件时内核会发送数据
if(forced_push(tp)){tcp_mark_push(tp,skb);__tcp_push_pending_frames(sk,mss_now,TCP_NAGLE_PUSH);}elseif(skb==tcp_send_head(sk))tcp_push_one(sk,mss_now);continue;wait_for_sndbuf:set_bit(SOCK_NOSPACE,&sk->sk_socket->flags);wait_for_memory:if(copied)tcp_push(sk,flags&~MSG_MORE,mss_now,TCP_NAGLE_PUSH);if((err=sk_stream_wait_memory(sk,&timeo))!=0)gotodo_error;mss_now=tcp_send_mss(sk,&size_goal,flags);}}out:if(copied)tcp_push(sk,flags,mss_now,tp->nonagle);release_sock(sk);returncopied+copied_syn;do_fault:if(!skb->len){tcp_unlink_write_queue(skb,sk);/* It is the one place in all of TCP, except connection
* reset, where we can be unlinking the send_head.
*/tcp_check_send_head(sk,skb);sk_wmem_free_skb(sk,skb);}do_error:if(copied+copied_syn)gotoout;out_err:err=sk_stream_error(sk,flags,err);release_sock(sk);returnerr;}EXPORT_SYMBOL(tcp_sendmsg);
staticbooltcp_write_xmit(structsock*sk,unsignedintmss_now,intnonagle,intpush_one,gfp_tgfp){structtcp_sock*tp=tcp_sk(sk);structsk_buff*skb;unsignedinttso_segs,sent_pkts;intcwnd_quota;intresult;sent_pkts=0;if(!push_one){/* Do MTU probing. */result=tcp_mtu_probe(sk);if(!result){returnfalse;}elseif(result>0){sent_pkts=1;}}// 循环等待队列, 获取发送队列的头部
while((skb=tcp_send_head(sk))){unsignedintlimit;tso_segs=tcp_init_tso_segs(sk,skb,mss_now);BUG_ON(!tso_segs);if(unlikely(tp->repair)&&tp->repair_queue==TCP_SEND_QUEUE)gotorepair;/* Skip network transmission */// 滑动窗口控制
cwnd_quota=tcp_cwnd_test(tp,skb);if(!cwnd_quota){if(push_one==2)/* Force out a loss probe pkt. */cwnd_quota=1;elsebreak;}if(unlikely(!tcp_snd_wnd_test(tp,skb,mss_now)))break;if(tso_segs==1){if(unlikely(!tcp_nagle_test(tp,skb,mss_now,(tcp_skb_is_last(sk,skb)?nonagle:TCP_NAGLE_PUSH))))break;}else{if(!push_one&&tcp_tso_should_defer(sk,skb))break;}/* TSQ : sk_wmem_alloc accounts skb truesize,
* including skb overhead. But thats OK.
*/if(atomic_read(&sk->sk_wmem_alloc)>=sysctl_tcp_limit_output_bytes){set_bit(TSQ_THROTTLED,&tp->tsq_flags);break;}limit=mss_now;if(tso_segs>1&&!tcp_urg_mode(tp))limit=tcp_mss_split_point(sk,skb,mss_now,min_t(unsignedint,cwnd_quota,sk->sk_gso_max_segs));if(skb->len>limit&&unlikely(tso_fragment(sk,skb,limit,mss_now,gfp)))break;TCP_SKB_CB(skb)->when=tcp_time_stamp;// 调用 tcp_transmit_skb 发送数据
if(unlikely(tcp_transmit_skb(sk,skb,1,gfp)))break;repair:/* Advance the send_head. This one is sent out.
* This call will increment packets_out.
*/tcp_event_new_data_sent(sk,skb);tcp_minshall_update(tp,mss_now,skb);sent_pkts+=tcp_skb_pcount(skb);if(push_one)break;}if(likely(sent_pkts)){if(tcp_in_cwnd_reduction(sk))tp->prr_out+=sent_pkts;/* Send one loss probe per tail loss episode. */if(push_one!=2)tcp_schedule_loss_probe(sk);tcp_cwnd_validate(sk);returnfalse;}return(push_one==2)||(!tp->packets_out&&tcp_send_head(sk));}
// https://github.com/torvalds/linux/blob/8bb495e3f02401ee6f76d1b1d77f3ac9f079e376/net/ipv4/tcp_output.c#L828-L957
staticinttcp_transmit_skb(structsock*sk,structsk_buff*skb,intclone_it,gfp_tgfp_mask){conststructinet_connection_sock*icsk=inet_csk(sk);structinet_sock*inet;structtcp_sock*tp;structtcp_skb_cb*tcb;structtcp_out_optionsopts;unsignedinttcp_options_size,tcp_header_size;structtcp_md5sig_key*md5;structtcphdr*th;interr;BUG_ON(!skb||!tcp_skb_pcount(skb));/* If congestion control is doing timestamping, we must
* take such a timestamp before we potentially clone/copy.
*/if(icsk->icsk_ca_ops->flags&TCP_CONG_RTT_STAMP)__net_timestamp(skb);// 克隆 skb
if(likely(clone_it)){conststructsk_buff*fclone=skb+1;if(unlikely(skb->fclone==SKB_FCLONE_ORIG&&fclone->fclone==SKB_FCLONE_CLONE))NET_INC_STATS_BH(sock_net(sk),LINUX_MIB_TCPSPURIOUS_RTX_HOSTQUEUES);if(unlikely(skb_cloned(skb)))skb=pskb_copy(skb,gfp_mask);elseskb=skb_clone(skb,gfp_mask);// 克隆 skb
if(unlikely(!skb))return-ENOBUFS;}inet=inet_sk(sk);tp=tcp_sk(sk);tcb=TCP_SKB_CB(skb);memset(&opts,0,sizeof(opts));if(unlikely(tcb->tcp_flags&TCPHDR_SYN))tcp_options_size=tcp_syn_options(sk,skb,&opts,&md5);elsetcp_options_size=tcp_established_options(sk,skb,&opts,&md5);tcp_header_size=tcp_options_size+sizeof(structtcphdr);if(tcp_packets_in_flight(tp)==0)tcp_ca_event(sk,CA_EVENT_TX_START);/* if no packet is in qdisc/device queue, then allow XPS to select
* another queue.
*/skb->ooo_okay=sk_wmem_alloc_get(sk)==0;skb_push(skb,tcp_header_size);skb_reset_transport_header(skb);skb_orphan(skb);skb->sk=sk;skb->destructor=(sysctl_tcp_limit_output_bytes>0)?tcp_wfree:sock_wfree;atomic_add(skb->truesize,&sk->sk_wmem_alloc);// 设置 tcp 头
/* Build TCP header and checksum it. */th=tcp_hdr(skb);th->source=inet->inet_sport;th->dest=inet->inet_dport;th->seq=htonl(tcb->seq);th->ack_seq=htonl(tp->rcv_nxt);*(((__be16*)th)+6)=htons(((tcp_header_size>>2)<<12)|tcb->tcp_flags);if(unlikely(tcb->tcp_flags&TCPHDR_SYN)){/* RFC1323: The window in SYN & SYN/ACK segments
* is never scaled.
*/th->window=htons(min(tp->rcv_wnd,65535U));}else{th->window=htons(tcp_select_window(sk));}th->check=0;th->urg_ptr=0;/* The urg_mode check is necessary during a below snd_una win probe */if(unlikely(tcp_urg_mode(tp)&&before(tcb->seq,tp->snd_up))){if(before(tp->snd_up,tcb->seq+0x10000)){th->urg_ptr=htons(tp->snd_up-tcb->seq);th->urg=1;}elseif(after(tcb->seq+0xFFFF,tp->snd_nxt)){th->urg_ptr=htons(0xFFFF);th->urg=1;}}tcp_options_write((__be32*)(th+1),tp,&opts);if(likely((tcb->tcp_flags&TCPHDR_SYN)==0))TCP_ECN_send(sk,skb,tcp_header_size);#ifdef CONFIG_TCP_MD5SIG
/* Calculate the MD5 hash, as we have all we need now */if(md5){sk_nocaps_add(sk,NETIF_F_GSO_MASK);tp->af_specific->calc_md5_hash(opts.hash_location,md5,sk,NULL,skb);}#endif
icsk->icsk_af_ops->send_check(sk,skb);if(likely(tcb->tcp_flags&TCPHDR_ACK))tcp_event_ack_sent(sk,tcp_skb_pcount(skb));if(skb->len!=tcp_header_size)tcp_event_data_sent(tp,sk);if(after(tcb->end_seq,tp->snd_nxt)||tcb->seq==tcb->end_seq)TCP_ADD_STATS(sock_net(sk),TCP_MIB_OUTSEGS,tcp_skb_pcount(skb));// 调用网络层的发送接口
err=icsk->icsk_af_ops->queue_xmit(skb,&inet->cork.fl);if(likely(err<=0))returnerr;tcp_enter_cwr(sk,1);returnnet_xmit_eval(err);}
// https://github.com/torvalds/linux/blob/8bb495e3f02401ee6f76d1b1d77f3ac9f079e376/net/ipv4/ip_output.c#L326-L413
intip_queue_xmit(structsk_buff*skb,structflowi*fl){structsock*sk=skb->sk;structinet_sock*inet=inet_sk(sk);structip_options_rcu*inet_opt;structflowi4*fl4;structrtable*rt;structiphdr*iph;intres;/* Skip all of this if the packet is already routed,
* f.e. by something like SCTP.
*/rcu_read_lock();inet_opt=rcu_dereference(inet->inet_opt);fl4=&fl->u.ip4;rt=skb_rtable(skb);if(rt!=NULL)gotopacket_routed;/* Make sure we can route this packet. */// 检查 socket 中是否缓存了路由信息
rt=(structrtable*)__sk_dst_check(sk,0);if(rt==NULL){__be32daddr;/* Use correct destination address if we have options. */daddr=inet->inet_daddr;if(inet_opt&&inet_opt->opt.srr)daddr=inet_opt->opt.faddr;/* If this fails, retransmit mechanism of transport layer will
* keep trying until route appears or the connection times
* itself out.
*/// 通过路由表查找路由, 并将其缓存在 socket 中
rt=ip_route_output_ports(sock_net(sk),fl4,sk,daddr,inet->inet_saddr,inet->inet_dport,inet->inet_sport,sk->sk_protocol,RT_CONN_FLAGS(sk),sk->sk_bound_dev_if);if(IS_ERR(rt))gotono_route;sk_setup_caps(sk,&rt->dst);}// 为 skb 设置路由信息
skb_dst_set_noref(skb,&rt->dst);packet_routed:if(inet_opt&&inet_opt->opt.is_strictroute&&rt->rt_uses_gateway)gotono_route;/* OK, we know where to send it, allocate and build IP header. */skb_push(skb,sizeof(structiphdr)+(inet_opt?inet_opt->opt.optlen:0));skb_reset_network_header(skb);iph=ip_hdr(skb);// 设置 IP 头等信息
*((__be16*)iph)=htons((4<<12)|(5<<8)|(inet->tos&0xff));if(ip_dont_fragment(sk,&rt->dst)&&!skb->local_df)iph->frag_off=htons(IP_DF);elseiph->frag_off=0;iph->ttl=ip_select_ttl(inet,&rt->dst);iph->protocol=sk->sk_protocol;ip_copy_addrs(iph,fl4);/* Transport layer set skb->h.foo itself. */if(inet_opt&&inet_opt->opt.optlen){iph->ihl+=inet_opt->opt.optlen>>2;ip_options_build(skb,&inet_opt->opt,inet->inet_daddr,rt,0);}ip_select_ident_more(iph,&rt->dst,sk,(skb_shinfo(skb)->gso_segs?:1)-1);skb->priority=sk->sk_priority;skb->mark=sk->sk_mark;// 调用 ip_local_out 函数发送 skb
res=ip_local_out(skb);rcu_read_unlock();returnres;no_route:rcu_read_unlock();IP_INC_STATS(sock_net(sk),IPSTATS_MIB_OUTNOROUTES);kfree_skb(skb);return-EHOSTUNREACH;}EXPORT_SYMBOL(ip_queue_xmit);
staticinlineintip_finish_output2(structsk_buff*skb){structdst_entry*dst=skb_dst(skb);structrtable*rt=(structrtable*)dst;structnet_device*dev=dst->dev;unsignedinthh_len=LL_RESERVED_SPACE(dev);structneighbour*neigh;u32nexthop;if(rt->rt_type==RTN_MULTICAST){IP_UPD_PO_STATS(dev_net(dev),IPSTATS_MIB_OUTMCAST,skb->len);}elseif(rt->rt_type==RTN_BROADCAST)IP_UPD_PO_STATS(dev_net(dev),IPSTATS_MIB_OUTBCAST,skb->len);/* Be paranoid, rather than too clever. */if(unlikely(skb_headroom(skb)<hh_len&&dev->header_ops)){structsk_buff*skb2;skb2=skb_realloc_headroom(skb,LL_RESERVED_SPACE(dev));if(skb2==NULL){kfree_skb(skb);return-ENOMEM;}if(skb->sk)skb_set_owner_w(skb2,skb->sk);consume_skb(skb);skb=skb2;}rcu_read_lock_bh();// 根据下一跳地址查找邻居项,没有没有找到就创建一个
nexthop=(__forceu32)rt_nexthop(rt,ip_hdr(skb)->daddr);neigh=__ipv4_neigh_lookup_noref(dev,nexthop);// 没有找到就创建一个
if(unlikely(!neigh))neigh=__neigh_create(&arp_tbl,&nexthop,dev,false);if(!IS_ERR(neigh)){intres=dst_neigh_output(dst,neigh,skb);// 调用 dst_neigh_output 函数向下层传递
rcu_read_unlock_bh();returnres;}rcu_read_unlock_bh();net_dbg_ratelimited("%s: No header cache and no neighbour!\n",__func__);kfree_skb(skb);return-EINVAL;}
// https://github.com/torvalds/linux/blob/8bb495e3f02401ee6f76d1b1d77f3ac9f079e376/net/core/dev.c#L2654-L2715
staticinlineint__dev_xmit_skb(structsk_buff*skb,structQdisc*q,structnet_device*dev,structnetdev_queue*txq){spinlock_t*root_lock=qdisc_lock(q);boolcontended;intrc;qdisc_pkt_len_init(skb);qdisc_calculate_pkt_len(skb,q);/*
* Heuristic to force contended enqueues to serialize on a
* separate lock before trying to get qdisc main lock.
* This permits __QDISC_STATE_RUNNING owner to get the lock more often
* and dequeue packets faster.
*/contended=qdisc_is_running(q);if(unlikely(contended))spin_lock(&q->busylock);spin_lock(root_lock);if(unlikely(test_bit(__QDISC_STATE_DEACTIVATED,&q->state))){kfree_skb(skb);rc=NET_XMIT_DROP;}elseif((q->flags&TCQ_F_CAN_BYPASS)&&!qdisc_qlen(q)&&qdisc_run_begin(q)){/*
* This is a work-conserving queue; there are no old skbs
* waiting to be sent out; and the qdisc is not running -
* xmit the skb directly.
*/if(!(dev->priv_flags&IFF_XMIT_DST_RELEASE))skb_dst_force(skb);qdisc_bstats_update(q,skb);if(sch_direct_xmit(skb,q,dev,txq,root_lock)){if(unlikely(contended)){spin_unlock(&q->busylock);contended=false;}__qdisc_run(q);}elseqdisc_run_end(q);rc=NET_XMIT_SUCCESS;}else{// 正常排队逻辑
// 将 skb 添加到发送队列中
skb_dst_force(skb);rc=q->enqueue(skb,q)&NET_XMIT_MASK;if(qdisc_run_begin(q)){if(unlikely(contended)){spin_unlock(&q->busylock);contended=false;}// 开始发送
__qdisc_run(q);}}spin_unlock(root_lock);if(unlikely(contended))spin_unlock(&q->busylock);returnrc;}
// net/core/dev.c
intdev_hard_start_xmit(structsk_buff*skb,structnet_device*dev,structnetdev_queue*txq){conststructnet_device_ops*ops=dev->netdev_ops;intrc=NETDEV_TX_OK;unsignedintskb_len;if(likely(!skb->next)){netdev_features_tfeatures;/*
* If device doesn't need skb->dst, release it right now while
* its hot in this cpu cache
*/if(dev->priv_flags&IFF_XMIT_DST_RELEASE)skb_dst_drop(skb);features=netif_skb_features(skb);if(vlan_tx_tag_present(skb)&&!vlan_hw_offload_capable(features,skb->vlan_proto)){skb=__vlan_put_tag(skb,skb->vlan_proto,vlan_tx_tag_get(skb));if(unlikely(!skb))gotoout;skb->vlan_tci=0;}/* If encapsulation offload request, verify we are testing
* hardware encapsulation features instead of standard
* features for the netdev
*/if(skb->encapsulation)features&=dev->hw_enc_features;if(netif_needs_gso(skb,features)){if(unlikely(dev_gso_segment(skb,features)))gotoout_kfree_skb;if(skb->next)gotogso;}else{if(skb_needs_linearize(skb,features)&&__skb_linearize(skb))gotoout_kfree_skb;/* If packet is not checksummed and device does not
* support checksumming for this protocol, complete
* checksumming here.
*/if(skb->ip_summed==CHECKSUM_PARTIAL){if(skb->encapsulation)skb_set_inner_transport_header(skb,skb_checksum_start_offset(skb));elseskb_set_transport_header(skb,skb_checksum_start_offset(skb));if(!(features&NETIF_F_ALL_CSUM)&&skb_checksum_help(skb))gotoout_kfree_skb;}}if(!list_empty(&ptype_all))dev_queue_xmit_nit(skb,dev);skb_len=skb->len;rc=ops->ndo_start_xmit(skb,dev);// 调用驱动的 ops 里的发送回调函数讲数据包传给网卡设备
trace_net_dev_xmit(skb,rc,dev,skb_len);if(rc==NETDEV_TX_OK)txq_trans_update(txq);returnrc;}......out_kfree_gso_skb:if(likely(skb->next==NULL)){skb->destructor=DEV_GSO_CB(skb)->destructor;consume_skb(skb);returnrc;}out_kfree_skb:kfree_skb(skb);out:returnrc;}