/**
* igb_open - Called when a network interface is made active
* @netdev: network interface device structure
*
* Returns 0 on success, negative value on failure
*
* The open entry point is called when a network interface is made
* active by the system (IFF_UP). At this point all resources needed
* for transmit and receive operations are allocated, the interrupt
* handler is registered with the OS, the watchdog timer is started,
* and the stack is notified that the interface is ready.
**/staticint__igb_open(structnet_device*netdev,boolresuming){structigb_adapter*adapter=netdev_priv(netdev);structe1000_hw*hw=&adapter->hw;structpci_dev*pdev=adapter->pdev;interr;inti;/* disallow open during test */if(test_bit(__IGB_TESTING,&adapter->state)){WARN_ON(resuming);return-EBUSY;}if(!resuming)pm_runtime_get_sync(&pdev->dev);netif_carrier_off(netdev);/* allocate transmit descriptors */// 分配传输描述符数组
err=igb_setup_all_tx_resources(adapter);if(err)gotoerr_setup_tx;/* allocate receive descriptors */// 分配接收描述符数组
err=igb_setup_all_rx_resources(adapter);if(err)gotoerr_setup_rx;igb_power_up_link(adapter);/* before we allocate an interrupt, we must be ready to handle it.
* Setting DEBUG_SHIRQ in the kernel makes it fire an interrupt
* as soon as we call pci_request_irq, so we have to setup our
* clean_rx handler before we do so.
*/igb_configure(adapter);// 注册中断处理函数
err=igb_request_irq(adapter);if(err)gotoerr_req_irq;/* Notify the stack of the actual queue counts. */err=netif_set_real_num_tx_queues(adapter->netdev,adapter->num_tx_queues);if(err)gotoerr_set_queues;err=netif_set_real_num_rx_queues(adapter->netdev,adapter->num_rx_queues);if(err)gotoerr_set_queues;/* From here on the code is the same as igb_up() */clear_bit(__IGB_DOWN,&adapter->state);// 启用 NAPI
for(i=0;i<adapter->num_q_vectors;i++)napi_enable(&(adapter->q_vector[i]->napi));/* Clear any pending interrupts. */rd32(E1000_ICR);igb_irq_enable(adapter);/* notify VFs that reset has been completed */if(adapter->vfs_allocated_count){u32reg_data=rd32(E1000_CTRL_EXT);reg_data|=E1000_CTRL_EXT_PFRSTD;wr32(E1000_CTRL_EXT,reg_data);}netif_tx_start_all_queues(netdev);if(!resuming)pm_runtime_put(&pdev->dev);/* start the watchdog. */hw->mac.get_link_status=1;schedule_work(&adapter->watchdog_task);return0;err_set_queues:igb_free_irq(adapter);err_req_irq:igb_release_hw_control(adapter);igb_power_down_link(adapter);igb_free_all_rx_resources(adapter);err_setup_rx:igb_free_all_tx_resources(adapter);err_setup_tx:igb_reset(adapter);if(!resuming)pm_runtime_put(&pdev->dev);returnerr;}
下面是描述符数组的具体创建过程:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
// https://github.com/torvalds/linux/blob/8bb495e3f02401ee6f76d1b1d77f3ac9f079e376/drivers/net/ethernet/intel/igb/igb_main.c#L3063-L3086
staticintigb_setup_all_rx_resources(structigb_adapter*adapter){structpci_dev*pdev=adapter->pdev;inti,err=0;for(i=0;i<adapter->num_rx_queues;i++){err=igb_setup_rx_resources(adapter->rx_ring[i]);if(err){dev_err(&pdev->dev,"Allocation for Rx Queue %u failed\n",i);for(i--;i>=0;i--)igb_free_rx_resources(adapter->rx_ring[i]);break;}}returnerr;}
// https://github.com/torvalds/linux/blob/8bb495e3f02401ee6f76d1b1d77f3ac9f079e376/drivers/net/ethernet/intel/igb/igb_main.c#L3023-L3060
/**
* igb_setup_rx_resources - allocate Rx resources (Descriptors)
* @rx_ring: Rx descriptor ring (for a specific queue) to setup
*
* Returns 0 on success, negative on failure
**/intigb_setup_rx_resources(structigb_ring*rx_ring){structdevice*dev=rx_ring->dev;intsize;size=sizeof(structigb_rx_buffer)*rx_ring->count;rx_ring->rx_buffer_info=vzalloc(size);if(!rx_ring->rx_buffer_info)gotoerr;/* Round up to nearest 4K */rx_ring->size=rx_ring->count*sizeof(unione1000_adv_rx_desc);rx_ring->size=ALIGN(rx_ring->size,4096);rx_ring->desc=dma_alloc_coherent(dev,rx_ring->size,&rx_ring->dma,GFP_KERNEL);if(!rx_ring->desc)gotoerr;rx_ring->next_to_alloc=0;rx_ring->next_to_clean=0;rx_ring->next_to_use=0;return0;err:vfree(rx_ring->rx_buffer_info);rx_ring->rx_buffer_info=NULL;dev_err(dev,"Unable to allocate memory for the Rx descriptor ring\n");return-ENOMEM;}
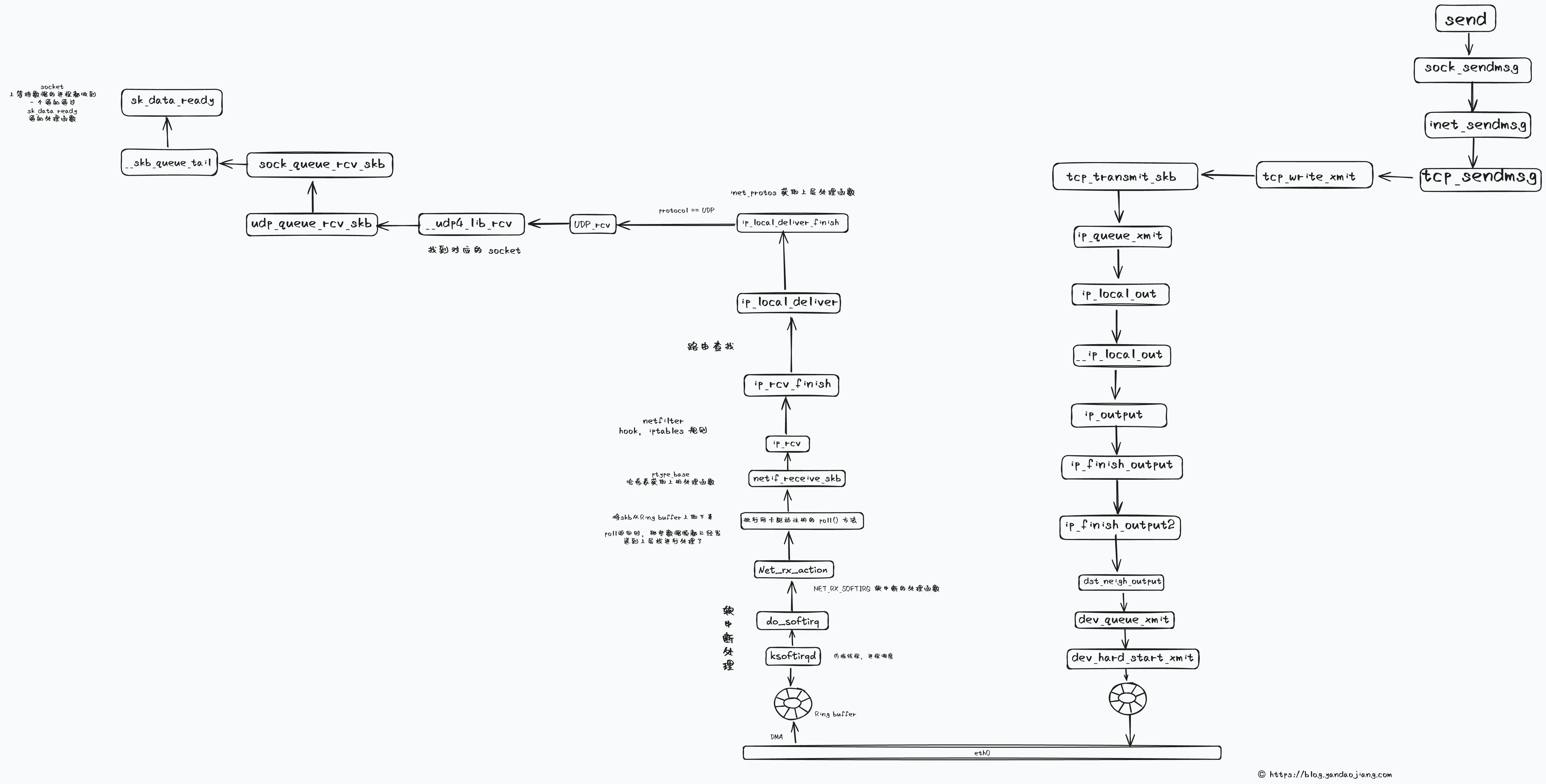
CPU 收到网卡发起硬中断之后,就会调用驱动注册的硬中断处理函数。对于 igb 网卡,这个处理函数就是在网卡启动这一节最后提到的 igb_mix_ring。
1
2
3
4
5
6
7
8
9
10
11
staticirqreturn_tigb_msix_ring(intirq,void*data){structigb_q_vector*q_vector=data;/* Write the ITR value calculated from the previous interrupt. */igb_write_itr(q_vector);napi_schedule(&q_vector->napi);returnIRQ_HANDLED;}
// https://github.com/torvalds/linux/blob/8bb495e3f02401ee6f76d1b1d77f3ac9f079e376/net/core/dev.c#L2874-L2879
/* Called with irq disabled */staticinlinevoid____napi_schedule(structsoftnet_data*sd,structnapi_struct*napi){list_add_tail(&napi->poll_list,&sd->poll_list);__raise_softirq_irqoff(NET_RX_SOFTIRQ);}
// https://github.com/torvalds/linux/blob/8bb495e3f02401ee6f76d1b1d77f3ac9f079e376/kernel/softirq.c#L763-L774
staticvoidrun_ksoftirqd(unsignedintcpu){local_irq_disable();// 关闭所在 CPU 的所有硬中断
if(local_softirq_pending()){__do_softirq();// 重新打开所在 CPU 的所有硬中断
rcu_note_context_switch(cpu);local_irq_enable();cond_resched();// 将 CPU 交还给调度器
return;}local_irq_enable();// 重新打开所在 CPU 的所有硬中断
}
这里如果硬中断写入了标记,那么在 local_softirq_pending 就能够读取到。在 __do_softirq 中就会根据当前 CPU 的软中断类型,调用注册的 action 方法。对于接收数据包来说就是 net_rx_action。
// https://github.com/torvalds/linux/blob/8bb495e3f02401ee6f76d1b1d77f3ac9f079e376/net/core/dev.c#L4149-L4242
staticvoidnet_rx_action(structsoftirq_action*h){structsoftnet_data*sd=&__get_cpu_var(softnet_data);// 该 CPU 的 softnet_data 统计
unsignedlongtime_limit=jiffies+2;// 该 CPU 的所有 NAPI 变量的总 time limit
unsignedlongtime_limit=jiffies+2;// 该 CPU 的所有 NAPI 变量的总 time limit
intbudget=netdev_budget;void*have;local_irq_disable();while(!list_empty(&sd->poll_list)){structnapi_struct*n;intwork,weight;/* If softirq window is exhuasted then punt.
* Allow this to run for 2 jiffies since which will allow
* an average latency of 1.5/HZ.
*/if(unlikely(budget<=0||time_after_eq(jiffies,time_limit)))gotosoftnet_break;local_irq_enable();/* Even though interrupts have been re-enabled, this
* access is safe because interrupts can only add new
* entries to the tail of this list, and only ->poll()
* calls can remove this head entry from the list.
*/n=list_first_entry(&sd->poll_list,structnapi_struct,poll_list);have=netpoll_poll_lock(n);weight=n->weight;/* This NAPI_STATE_SCHED test is for avoiding a race
* with netpoll's poll_napi(). Only the entity which
* obtains the lock and sees NAPI_STATE_SCHED set will
* actually make the ->poll() call. Therefore we avoid
* accidentally calling ->poll() when NAPI is not scheduled.
*/work=0;if(test_bit(NAPI_STATE_SCHED,&n->state)){work=n->poll(n,weight);trace_napi_poll(n);}WARN_ON_ONCE(work>weight);budget-=work;local_irq_disable();/* Drivers must not modify the NAPI state if they
* consume the entire weight. In such cases this code
* still "owns" the NAPI instance and therefore can
* move the instance around on the list at-will.
*/if(unlikely(work==weight)){if(unlikely(napi_disable_pending(n))){local_irq_enable();napi_complete(n);local_irq_disable();}else{if(n->gro_list){/* flush too old packets
* If HZ < 1000, flush all packets.
*/local_irq_enable();napi_gro_flush(n,HZ>=1000);local_irq_disable();}list_move_tail(&n->poll_list,&sd->poll_list);}}netpoll_poll_unlock(have);}out:net_rps_action_and_irq_enable(sd);#ifdef CONFIG_NET_DMA
/*
* There may not be any more sk_buffs coming right now, so push
* any pending DMA copies to hardware
*/dma_issue_pending_all();#endif
return;softnet_break:sd->time_squeeze++;__raise_softirq_irqoff(NET_RX_SOFTIRQ);gotoout;}
staticint__netif_receive_skb_core(structsk_buff*skb,boolpfmemalloc){structpacket_type*ptype,*pt_prev;rx_handler_func_t*rx_handler;structnet_device*orig_dev;structnet_device*null_or_dev;booldeliver_exact=false;intret=NET_RX_DROP;__be16type;net_timestamp_check(!netdev_tstamp_prequeue,skb);trace_netif_receive_skb(skb);/* if we've gotten here through NAPI, check netpoll */if(netpoll_receive_skb(skb))gotoout;orig_dev=skb->dev;skb_reset_network_header(skb);if(!skb_transport_header_was_set(skb))skb_reset_transport_header(skb);skb_reset_mac_len(skb);pt_prev=NULL;rcu_read_lock();another_round:skb->skb_iif=skb->dev->ifindex;__this_cpu_inc(softnet_data.processed);if(skb->protocol==cpu_to_be16(ETH_P_8021Q)||skb->protocol==cpu_to_be16(ETH_P_8021AD)){skb=vlan_untag(skb);if(unlikely(!skb))gotounlock;}#ifdef CONFIG_NET_CLS_ACT
if(skb->tc_verd&TC_NCLS){skb->tc_verd=CLR_TC_NCLS(skb->tc_verd);gotoncls;}#endif
if(pfmemalloc)gotoskip_taps;list_for_each_entry_rcu(ptype,&ptype_all,list){// 抓包
if(!ptype->dev||ptype->dev==skb->dev){if(pt_prev)ret=deliver_skb(skb,pt_prev,orig_dev);pt_prev=ptype;}}skip_taps:#ifdef CONFIG_NET_CLS_ACT
skb=handle_ing(skb,&pt_prev,&ret,orig_dev);if(!skb)gotounlock;ncls:#endif
if(pfmemalloc&&!skb_pfmemalloc_protocol(skb))gotodrop;if(vlan_tx_tag_present(skb)){if(pt_prev){ret=deliver_skb(skb,pt_prev,orig_dev);pt_prev=NULL;}if(vlan_do_receive(&skb))gotoanother_round;elseif(unlikely(!skb))gotounlock;}rx_handler=rcu_dereference(skb->dev->rx_handler);if(rx_handler){if(pt_prev){ret=deliver_skb(skb,pt_prev,orig_dev);pt_prev=NULL;}switch(rx_handler(&skb)){caseRX_HANDLER_CONSUMED:ret=NET_RX_SUCCESS;gotounlock;caseRX_HANDLER_ANOTHER:gotoanother_round;caseRX_HANDLER_EXACT:deliver_exact=true;caseRX_HANDLER_PASS:break;default:BUG();}}if(vlan_tx_nonzero_tag_present(skb))skb->pkt_type=PACKET_OTHERHOST;/* deliver only exact match when indicated */null_or_dev=deliver_exact?skb->dev:NULL;type=skb->protocol;list_for_each_entry_rcu(ptype,&ptype_base[ntohs(type)&PTYPE_HASH_MASK],list){// 根据协议送往协议栈处理
if(ptype->type==type&&(ptype->dev==null_or_dev||ptype->dev==skb->dev||ptype->dev==orig_dev)){if(pt_prev)ret=deliver_skb(skb,pt_prev,orig_dev);pt_prev=ptype;}}if(pt_prev){if(unlikely(skb_orphan_frags(skb,GFP_ATOMIC)))gotodrop;elseret=pt_prev->func(skb,skb->dev,pt_prev,orig_dev);}else{drop:atomic_long_inc(&skb->dev->rx_dropped);kfree_skb(skb);/* Jamal, now you will not able to escape explaining
* me how you were going to use this. :-)
*/ret=NET_RX_DROP;}unlock:rcu_read_unlock();out:returnret;}
/*
* Main IP Receive routine.
*/intip_rcv(structsk_buff*skb,structnet_device*dev,structpacket_type*pt,structnet_device*orig_dev){conststructiphdr*iph;u32len;/* When the interface is in promisc. mode, drop all the crap
* that it receives, do not try to analyse it.
*/if(skb->pkt_type==PACKET_OTHERHOST)gotodrop;IP_UPD_PO_STATS_BH(dev_net(dev),IPSTATS_MIB_IN,skb->len);// 更新统计信息
if((skb=skb_share_check(skb,GFP_ATOMIC))==NULL){IP_INC_STATS_BH(dev_net(dev),IPSTATS_MIB_INDISCARDS);gotoout;}if(!pskb_may_pull(skb,sizeof(structiphdr)))gotoinhdr_error;iph=ip_hdr(skb);// 校验
/*
* RFC1122: 3.2.1.2 MUST silently discard any IP frame that fails the checksum.
*
* Is the datagram acceptable?
*
* 1. Length at least the size of an ip header
* 2. Version of 4
* 3. Checksums correctly. [Speed optimisation for later, skip loopback checksums]
* 4. Doesn't have a bogus length
*/if(iph->ihl<5||iph->version!=4)gotoinhdr_error;if(!pskb_may_pull(skb,iph->ihl*4))gotoinhdr_error;iph=ip_hdr(skb);if(unlikely(ip_fast_csum((u8*)iph,iph->ihl)))gotocsum_error;len=ntohs(iph->tot_len);if(skb->len<len){IP_INC_STATS_BH(dev_net(dev),IPSTATS_MIB_INTRUNCATEDPKTS);gotodrop;}elseif(len<(iph->ihl*4))gotoinhdr_error;/* Our transport medium may have padded the buffer out. Now we know it
* is IP we can trim to the true length of the frame.
* Note this now means skb->len holds ntohs(iph->tot_len).
*/if(pskb_trim_rcsum(skb,len)){IP_INC_STATS_BH(dev_net(dev),IPSTATS_MIB_INDISCARDS);gotodrop;}/* Remove any debris in the socket control block */memset(IPCB(skb),0,sizeof(structinet_skb_parm));/* Must drop socket now because of tproxy. */skb_orphan(skb);returnNF_HOOK(NFPROTO_IPV4,NF_INET_PRE_ROUTING,skb,dev,NULL,ip_rcv_finish);csum_error:IP_INC_STATS_BH(dev_net(dev),IPSTATS_MIB_CSUMERRORS);inhdr_error:IP_INC_STATS_BH(dev_net(dev),IPSTATS_MIB_INHDRERRORS);drop:kfree_skb(skb);out:returnNET_RX_DROP;}
// https://github.com/torvalds/linux/blob/8bb495e3f02401ee6f76d1b1d77f3ac9f079e376/net/ipv4/ip_input.c#L189-L242
staticintip_local_deliver_finish(structsk_buff*skb){structnet*net=dev_net(skb->dev);__skb_pull(skb,ip_hdrlen(skb));/* Point into the IP datagram, just past the header. */skb_reset_transport_header(skb);rcu_read_lock();{intprotocol=ip_hdr(skb)->protocol;conststructnet_protocol*ipprot;intraw;resubmit:raw=raw_local_deliver(skb,protocol);ipprot=rcu_dereference(inet_protos[protocol]);if(ipprot!=NULL){intret;if(!ipprot->no_policy){if(!xfrm4_policy_check(NULL,XFRM_POLICY_IN,skb)){kfree_skb(skb);gotoout;}nf_reset(skb);}ret=ipprot->handler(skb);if(ret<0){protocol=-ret;gotoresubmit;}IP_INC_STATS_BH(net,IPSTATS_MIB_INDELIVERS);}else{if(!raw){if(xfrm4_policy_check(NULL,XFRM_POLICY_IN,skb)){IP_INC_STATS_BH(net,IPSTATS_MIB_INUNKNOWNPROTOS);icmp_send(skb,ICMP_DEST_UNREACH,ICMP_PROT_UNREACH,0);}kfree_skb(skb);}else{IP_INC_STATS_BH(net,IPSTATS_MIB_INDELIVERS);consume_skb(skb);}}}out:rcu_read_unlock();return0;}
https://github.com/torvalds/linux/blob/8bb495e3f02401ee6f76d1b1d77f3ac9f079e376/net/ipv4/udp.c#L1671-L1763
int__udp4_lib_rcv(structsk_buff*skb,structudp_table*udptable,intproto){structsock*sk;structudphdr*uh;unsignedshortulen;structrtable*rt=skb_rtable(skb);__be32saddr,daddr;structnet*net=dev_net(skb->dev);/*
* Validate the packet.
*/if(!pskb_may_pull(skb,sizeof(structudphdr)))gotodrop;/* No space for header. */uh=udp_hdr(skb);ulen=ntohs(uh->len);saddr=ip_hdr(skb)->saddr;daddr=ip_hdr(skb)->daddr;if(ulen>skb->len)gotoshort_packet;if(proto==IPPROTO_UDP){/* UDP validates ulen. */if(ulen<sizeof(*uh)||pskb_trim_rcsum(skb,ulen))gotoshort_packet;uh=udp_hdr(skb);}if(udp4_csum_init(skb,uh,proto))gotocsum_error;if(rt->rt_flags&(RTCF_BROADCAST|RTCF_MULTICAST))return__udp4_lib_mcast_deliver(net,skb,uh,saddr,daddr,udptable);sk=__udp4_lib_lookup_skb(skb,uh->source,uh->dest,udptable);if(sk!=NULL){intret=udp_queue_rcv_skb(sk,skb);sock_put(sk);/* a return value > 0 means to resubmit the input, but
* it wants the return to be -protocol, or 0
*/if(ret>0)return-ret;return0;}if(!xfrm4_policy_check(NULL,XFRM_POLICY_IN,skb))gotodrop;nf_reset(skb);/* No socket. Drop packet silently, if checksum is wrong */if(udp_lib_checksum_complete(skb))gotocsum_error;UDP_INC_STATS_BH(net,UDP_MIB_NOPORTS,proto==IPPROTO_UDPLITE);icmp_send(skb,ICMP_DEST_UNREACH,ICMP_PORT_UNREACH,0);/*
* Hmm. We got an UDP packet to a port to which we
* don't wanna listen. Ignore it.
*/kfree_skb(skb);return0;short_packet:LIMIT_NETDEBUG(KERN_DEBUG"UDP%s: short packet: From %pI4:%u %d/%d to %pI4:%u\n",proto==IPPROTO_UDPLITE?"Lite":"",&saddr,ntohs(uh->source),ulen,skb->len,&daddr,ntohs(uh->dest));gotodrop;csum_error:/*
* RFC1122: OK. Discards the bad packet silently (as far as
* the network is concerned, anyway) as per 4.1.3.4 (MUST).
*/LIMIT_NETDEBUG(KERN_DEBUG"UDP%s: bad checksum. From %pI4:%u to %pI4:%u ulen %d\n",proto==IPPROTO_UDPLITE?"Lite":"",&saddr,ntohs(uh->source),&daddr,ntohs(uh->dest),ulen);UDP_INC_STATS_BH(net,UDP_MIB_CSUMERRORS,proto==IPPROTO_UDPLITE);drop:UDP_INC_STATS_BH(net,UDP_MIB_INERRORS,proto==IPPROTO_UDPLITE);kfree_skb(skb);return0;}
// https://github.com/torvalds/linux/blob/8bb495e3f02401ee6f76d1b1d77f3ac9f079e376/net/ipv4/udp.c#L1440-L1547
intudp_queue_rcv_skb(structsock*sk,structsk_buff*skb){structudp_sock*up=udp_sk(sk);intrc;intis_udplite=IS_UDPLITE(sk);/*
* Charge it to the socket, dropping if the queue is full.
*/if(!xfrm4_policy_check(sk,XFRM_POLICY_IN,skb))gotodrop;nf_reset(skb);if(static_key_false(&udp_encap_needed)&&up->encap_type){int(*encap_rcv)(structsock*sk,structsk_buff*skb);/*
* This is an encapsulation socket so pass the skb to
* the socket's udp_encap_rcv() hook. Otherwise, just
* fall through and pass this up the UDP socket.
* up->encap_rcv() returns the following value:
* =0 if skb was successfully passed to the encap
* handler or was discarded by it.
* >0 if skb should be passed on to UDP.
* <0 if skb should be resubmitted as proto -N
*//* if we're overly short, let UDP handle it */encap_rcv=ACCESS_ONCE(up->encap_rcv);if(skb->len>sizeof(structudphdr)&&encap_rcv!=NULL){intret;ret=encap_rcv(sk,skb);if(ret<=0){UDP_INC_STATS_BH(sock_net(sk),UDP_MIB_INDATAGRAMS,is_udplite);return-ret;}}/* FALLTHROUGH -- it's a UDP Packet */}/*
* UDP-Lite specific tests, ignored on UDP sockets
*/if((is_udplite&UDPLITE_RECV_CC)&&UDP_SKB_CB(skb)->partial_cov){/*
* MIB statistics other than incrementing the error count are
* disabled for the following two types of errors: these depend
* on the application settings, not on the functioning of the
* protocol stack as such.
*
* RFC 3828 here recommends (sec 3.3): "There should also be a
* way ... to ... at least let the receiving application block
* delivery of packets with coverage values less than a value
* provided by the application."
*/if(up->pcrlen==0){/* full coverage was set */LIMIT_NETDEBUG(KERN_WARNING"UDPLite: partial coverage %d while full coverage %d requested\n",UDP_SKB_CB(skb)->cscov,skb->len);gotodrop;}/* The next case involves violating the min. coverage requested
* by the receiver. This is subtle: if receiver wants x and x is
* greater than the buffersize/MTU then receiver will complain
* that it wants x while sender emits packets of smaller size y.
* Therefore the above ...()->partial_cov statement is essential.
*/if(UDP_SKB_CB(skb)->cscov<up->pcrlen){LIMIT_NETDEBUG(KERN_WARNING"UDPLite: coverage %d too small, need min %d\n",UDP_SKB_CB(skb)->cscov,up->pcrlen);gotodrop;}}if(rcu_access_pointer(sk->sk_filter)&&udp_lib_checksum_complete(skb))gotocsum_error;if(sk_rcvqueues_full(sk,skb,sk->sk_rcvbuf))gotodrop;rc=0;ipv4_pktinfo_prepare(skb);bh_lock_sock(sk);if(!sock_owned_by_user(sk))rc=__udp_queue_rcv_skb(sk,skb);elseif(sk_add_backlog(sk,skb,sk->sk_rcvbuf)){bh_unlock_sock(sk);gotodrop;}bh_unlock_sock(sk);returnrc;csum_error:UDP_INC_STATS_BH(sock_net(sk),UDP_MIB_CSUMERRORS,is_udplite);drop:UDP_INC_STATS_BH(sock_net(sk),UDP_MIB_INERRORS,is_udplite);atomic_inc(&sk->sk_drops);kfree_skb(skb);return-1;}